Multiple regression model - additive models
Jan Vávra
Exercise 5
Download this R markdown as: R, Rmd.
Outline of the lab session
- Multiple regression model with categorical covariate of multiple levels
- Additive model - combination of numeric and categorical covariates
- Model selection strategies
Loading the data and libraries
The dataset mtcars (available under the standard R
installation) will be used for the purposes of this lab session. Some
insight about the data can be taken from the help session (command
?mtcars) or from some outputs provided below.
library(colorspace)
head(mtcars)## mpg cyl disp hp drat wt qsec vs am gear carb
## Mazda RX4 21.0 6 160 110 3.90 2.620 16.46 0 1 4 4
## Mazda RX4 Wag 21.0 6 160 110 3.90 2.875 17.02 0 1 4 4
## Datsun 710 22.8 4 108 93 3.85 2.320 18.61 1 1 4 1
## Hornet 4 Drive 21.4 6 258 110 3.08 3.215 19.44 1 0 3 1
## Hornet Sportabout 18.7 8 360 175 3.15 3.440 17.02 0 0 3 2
## Valiant 18.1 6 225 105 2.76 3.460 20.22 1 0 3 1str(mtcars)## 'data.frame': 32 obs. of 11 variables:
## $ mpg : num 21 21 22.8 21.4 18.7 18.1 14.3 24.4 22.8 19.2 ...
## $ cyl : num 6 6 4 6 8 6 8 4 4 6 ...
## $ disp: num 160 160 108 258 360 ...
## $ hp : num 110 110 93 110 175 105 245 62 95 123 ...
## $ drat: num 3.9 3.9 3.85 3.08 3.15 2.76 3.21 3.69 3.92 3.92 ...
## $ wt : num 2.62 2.88 2.32 3.21 3.44 ...
## $ qsec: num 16.5 17 18.6 19.4 17 ...
## $ vs : num 0 0 1 1 0 1 0 1 1 1 ...
## $ am : num 1 1 1 0 0 0 0 0 0 0 ...
## $ gear: num 4 4 4 3 3 3 3 4 4 4 ...
## $ carb: num 4 4 1 1 2 1 4 2 2 4 ...summary(mtcars)## mpg cyl disp hp drat wt
## Min. :10.40 Min. :4.000 Min. : 71.1 Min. : 52.0 Min. :2.760 Min. :1.513
## 1st Qu.:15.43 1st Qu.:4.000 1st Qu.:120.8 1st Qu.: 96.5 1st Qu.:3.080 1st Qu.:2.581
## Median :19.20 Median :6.000 Median :196.3 Median :123.0 Median :3.695 Median :3.325
## Mean :20.09 Mean :6.188 Mean :230.7 Mean :146.7 Mean :3.597 Mean :3.217
## 3rd Qu.:22.80 3rd Qu.:8.000 3rd Qu.:326.0 3rd Qu.:180.0 3rd Qu.:3.920 3rd Qu.:3.610
## Max. :33.90 Max. :8.000 Max. :472.0 Max. :335.0 Max. :4.930 Max. :5.424
## qsec vs am gear carb
## Min. :14.50 Min. :0.0000 Min. :0.0000 Min. :3.000 Min. :1.000
## 1st Qu.:16.89 1st Qu.:0.0000 1st Qu.:0.0000 1st Qu.:3.000 1st Qu.:2.000
## Median :17.71 Median :0.0000 Median :0.0000 Median :4.000 Median :2.000
## Mean :17.85 Mean :0.4375 Mean :0.4062 Mean :3.688 Mean :2.812
## 3rd Qu.:18.90 3rd Qu.:1.0000 3rd Qu.:1.0000 3rd Qu.:4.000 3rd Qu.:4.000
## Max. :22.90 Max. :1.0000 Max. :1.0000 Max. :5.000 Max. :8.000Categorical predictor variable
Finally, we will consider a regression dependence of a continuous variable \(Y\) on some categorical covariate \(X\) (taking more than 2 levels). We will consider the number of cylinders (there are four, six, and eight cylinder cars in the data set). Note, that the categorical covariate can be either assumed to be nominal or, also, ordinal.
par(mfrow = c(1,1), mar = c(4,4,0.5,0.5))
boxplot(mpg ~ cyl, data = mtcars, col = "lightblue")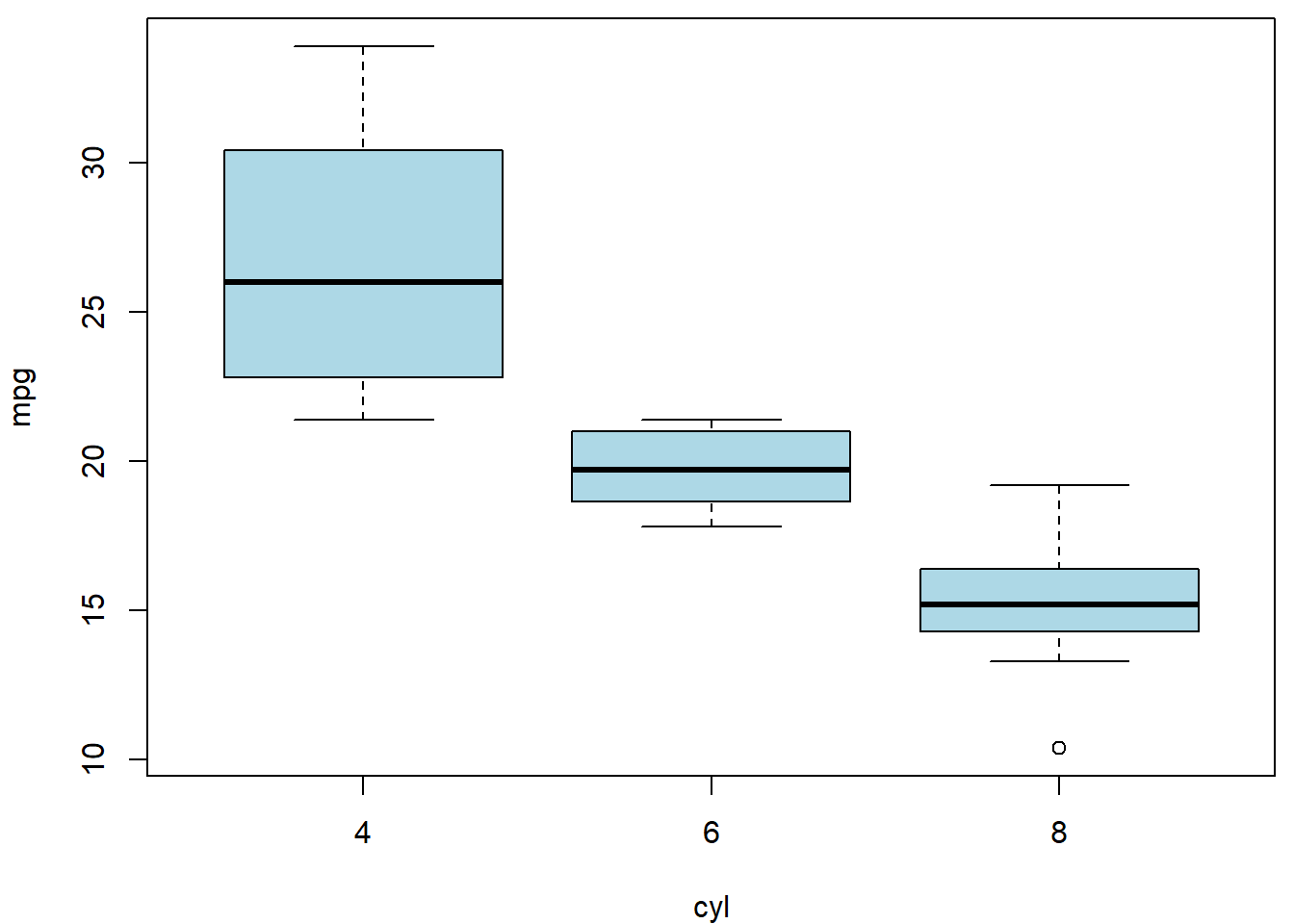
Compare and explain the following models:
fit1 <- lm(mpg ~ cyl, data = mtcars)
summary(fit1)##
## Call:
## lm(formula = mpg ~ cyl, data = mtcars)
##
## Residuals:
## Min 1Q Median 3Q Max
## -4.9814 -2.1185 0.2217 1.0717 7.5186
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 37.8846 2.0738 18.27 < 2e-16 ***
## cyl -2.8758 0.3224 -8.92 6.11e-10 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 3.206 on 30 degrees of freedom
## Multiple R-squared: 0.7262, Adjusted R-squared: 0.7171
## F-statistic: 79.56 on 1 and 30 DF, p-value: 6.113e-10fit2 <- lm(mpg ~ as.factor(cyl), data = mtcars)
summary(fit2)##
## Call:
## lm(formula = mpg ~ as.factor(cyl), data = mtcars)
##
## Residuals:
## Min 1Q Median 3Q Max
## -5.2636 -1.8357 0.0286 1.3893 7.2364
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 26.6636 0.9718 27.437 < 2e-16 ***
## as.factor(cyl)6 -6.9208 1.5583 -4.441 0.000119 ***
## as.factor(cyl)8 -11.5636 1.2986 -8.905 8.57e-10 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 3.223 on 29 degrees of freedom
## Multiple R-squared: 0.7325, Adjusted R-squared: 0.714
## F-statistic: 39.7 on 2 and 29 DF, p-value: 4.979e-09fit3 <- lm(mpg ~ cyl + I(cyl^2), data = mtcars)
summary(fit3)##
## Call:
## lm(formula = mpg ~ cyl + I(cyl^2), data = mtcars)
##
## Residuals:
## Min 1Q Median 3Q Max
## -5.2636 -1.8357 0.0286 1.3893 7.2364
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 47.3390 11.6471 4.064 0.000336 ***
## cyl -6.3078 4.1723 -1.512 0.141400
## I(cyl^2) 0.2847 0.3451 0.825 0.416072
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 3.223 on 29 degrees of freedom
## Multiple R-squared: 0.7325, Adjusted R-squared: 0.714
## F-statistic: 39.7 on 2 and 29 DF, p-value: 4.979e-09Individual work
- What are other possible parametrizations that can be used?
- Compare the following model with the model denoted as
fit2.
mtcars$dummy1 <- as.numeric(mtcars$cyl == 4)
mtcars$dummy1[mtcars$cyl == 8] <- -1
mtcars$dummy2 <- as.numeric(mtcars$cyl == 6)
mtcars$dummy2[mtcars$cyl == 8] <- -1
fit4 <- lm(mpg ~ dummy1 + dummy2, data = mtcars)
summary(fit4)##
## Call:
## lm(formula = mpg ~ dummy1 + dummy2, data = mtcars)
##
## Residuals:
## Min 1Q Median 3Q Max
## -5.2636 -1.8357 0.0286 1.3893 7.2364
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 20.5022 0.5935 34.543 < 2e-16 ***
## dummy1 6.1615 0.8167 7.544 2.57e-08 ***
## dummy2 -0.7593 0.9203 -0.825 0.416
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 3.223 on 29 degrees of freedom
## Multiple R-squared: 0.7325, Adjusted R-squared: 0.714
## F-statistic: 39.7 on 2 and 29 DF, p-value: 4.979e-09- Can you reconstruct model
fit2from the model above (fit4)? Look at the output of thesummary()function and explain the statistical tests that are provided for each column of the summary table (in modelfit2and modelfit4). - Think of some other parametrization that could be suitable and try to implement them in the R software.
Categorical and numeric covariate as regressors
What happens when we add the weight of the car wt into
the formula of model fit2?
mtcars$fcyl <- factor(mtcars$cyl)
fit5 <- lm(mpg ~ fcyl + wt, data = mtcars)
summary(fit5)##
## Call:
## lm(formula = mpg ~ fcyl + wt, data = mtcars)
##
## Residuals:
## Min 1Q Median 3Q Max
## -4.5890 -1.2357 -0.5159 1.3845 5.7915
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 33.9908 1.8878 18.006 < 2e-16 ***
## fcyl6 -4.2556 1.3861 -3.070 0.004718 **
## fcyl8 -6.0709 1.6523 -3.674 0.000999 ***
## wt -3.2056 0.7539 -4.252 0.000213 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 2.557 on 28 degrees of freedom
## Multiple R-squared: 0.8374, Adjusted R-squared: 0.82
## F-statistic: 48.08 on 3 and 28 DF, p-value: 3.594e-11The model has 4 coefficients: \[ \mathsf{E} \left[Y | F = f, X = x \right] = \beta_1 + \beta_2 \mathbb{1} [f = 6] + \beta_3 \mathbb{1} [f = 8] + \beta_4 x \] with the following interpretation: \[ \begin{aligned} \beta_1 &= \mathsf{E} \left[Y | F = 4, X = 0 \right], \\ \beta_2 &= \mathsf{E} \left[Y | F = 6, X = x \right] - \mathsf{E} \left[Y | F = 4, X = x \right], \\ \beta_3 &= \mathsf{E} \left[Y | F = 8, X = x \right] - \mathsf{E} \left[Y | F = 4, X = x \right], \\ \beta_4 &= \mathsf{E} \left[Y | F = f, X = x+1 \right] - \mathsf{E} \left[Y | F = f, X = x \right]. \end{aligned} \]
Especially, the difference between two levels of the factor variable is always the same regardless of the value \(x\). Similarly, the linear trend has the same slope regardless of the factor \(f\). Hence, the resulting fit are 3 parallel lines - one for each factor group:
PCH <- c(21, 22, 24)
DARK <- rainbow_hcl(3, c = 80, l = 35)
COL <- rainbow_hcl(3, c = 80, l = 50)
BGC <- rainbow_hcl(3, c = 80, l = 70)
names(PCH) <- names(COL) <- names(BGC) <- levels(mtcars$fcyl)
par(mfrow = c(1,1), mar = c(4,4,0.5,0.5))
plot(mpg ~ wt, data = mtcars,
ylab = "Miles per gallon",
xlab = "Weight [1000 lbs]",
pch = PCH[fcyl], col = COL[fcyl], bg = BGC[fcyl])
abline(a = coef(fit5)[1], b = coef(fit5)[4],
col = COL[1], lwd = 2)
abline(a = coef(fit5)[1]+coef(fit5)[2], b = coef(fit5)[4],
col = COL[2], lwd = 2)
abline(a = coef(fit5)[1]+coef(fit5)[3], b = coef(fit5)[4],
col = COL[3], lwd = 2)
legend("topright", legend = levels(mtcars$fcyl), bty = "n",
col = COL, pt.bg = BGC, pch = PCH, lty = 1, lwd = 2)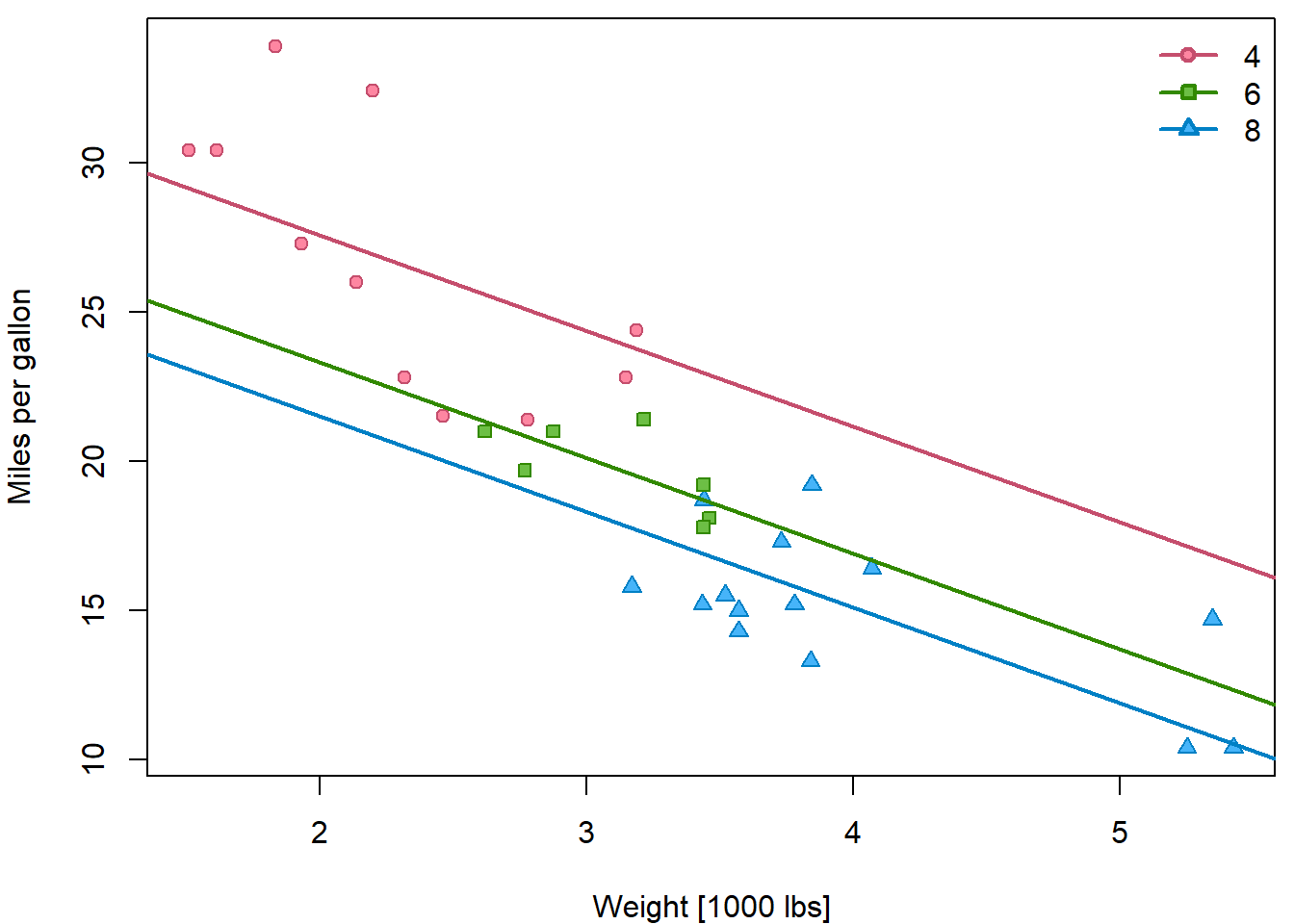
Individual work
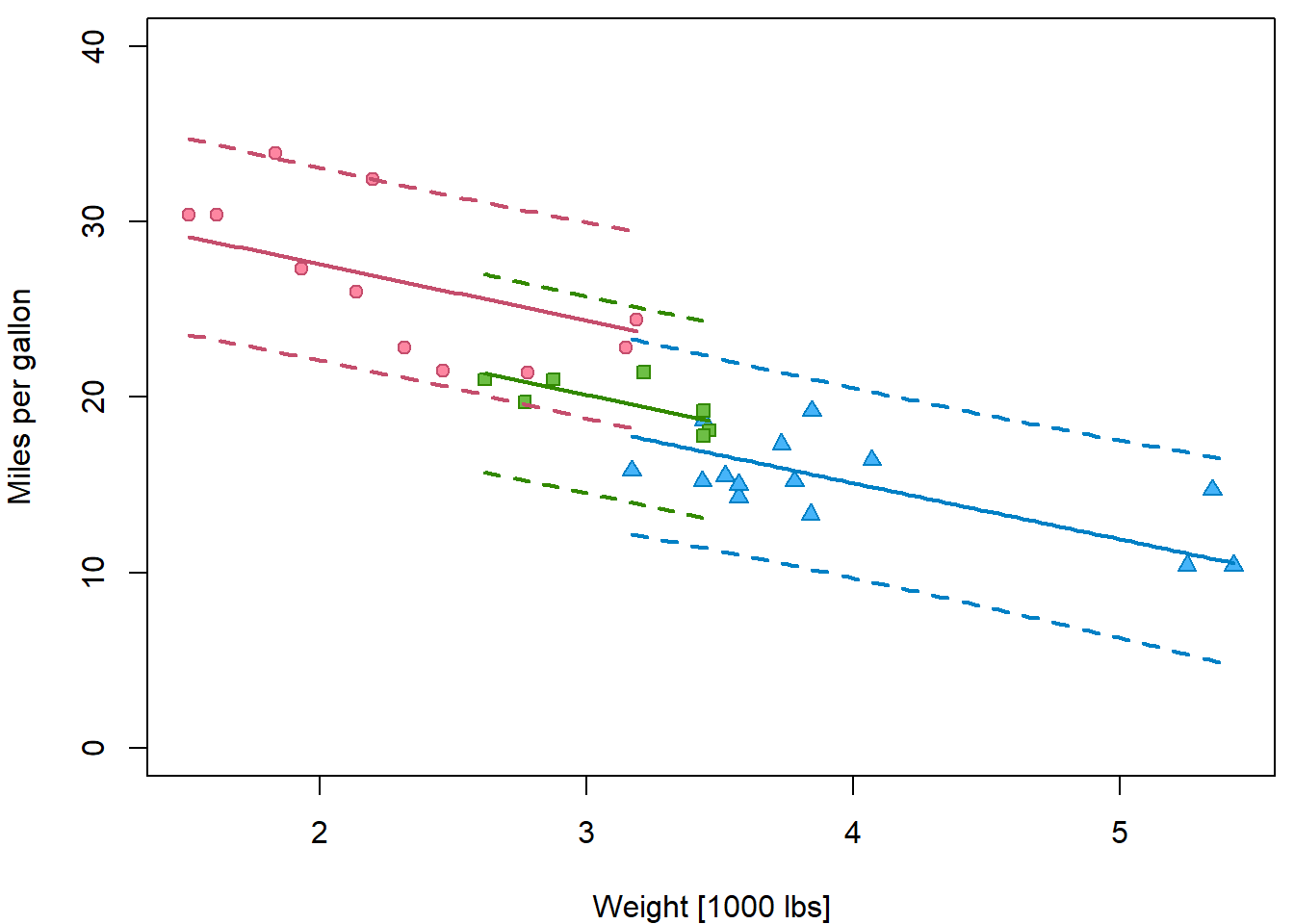
Insert prediction intervals into the previous plot by following these steps:
- Compute
rangeofwtfor each level offcyl. - Create
newdatafor eachfcyllevel separately with a grid ofwtvalues in the range specific for this cylinder count. - Use
predictonfit5three times for these 3 new datasets with optioninterval="prediction". - Instead of
ablinefor plotting the estimated line uselineson the point estimatefitto plot it only on a relevant range. - Insert lines for lower and upper bounds, choose appropriate colors
and different line type
ltyand widthlwd.
ranges <- tapply(mtcars$wt, mtcars$fcyl, range)
par(mfrow = c(1,1), mar = c(4,4,0.5,0.5))
plot(mpg ~ wt, data = mtcars,
ylab = "Miles per gallon",
xlab = "Weight [1000 lbs]",
ylim = c(0,40),
pch = PCH[fcyl], col = COL[fcyl], bg = BGC[fcyl])
for(l in levels(mtcars$fcyl)){
xgrid <- seq(ranges[[l]][1], ranges[[l]][2], length.out = 101)
newdata <- data.frame(fcyl = l,
wt = xgrid)
pred <- predict(fit5, newdata = newdata, interval = "prediction")
lines(x = xgrid, y = pred[,"fit"], col = COL[l], lwd = 2)
lines(x = xgrid, y = pred[,"lwr"], col = COL[l], lwd = 2, lty = 2)
lines(x = xgrid, y = pred[,"upr"], col = COL[l], lwd = 2, lty = 2)
}
Additive model
Let us consider a model that tries to explain miles per gallon
mpg of a vehicle by: disp, hp and
drat as in previous exercise.
For simplicity, we now consider linear parametrizations and covariates that only require single column in the model matrix. The following model (as well as all the models above) is additive. The effect of one covariate does not depend on the values of other covariates: \[ \beta_k = \mathsf{E} \left[Y | X_k = x_k + 1, \mathbf{X}_{-k} = \mathbf{x}_{-k}\right] - \left[Y | \mathbf{X} = \mathbf{x} \right] \]
fit_add <- lm(mpg ~ disp + hp + drat, data = mtcars)
summary(fit_add)##
## Call:
## lm(formula = mpg ~ disp + hp + drat, data = mtcars)
##
## Residuals:
## Min 1Q Median 3Q Max
## -5.1225 -1.8454 -0.4456 1.1342 6.4958
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 19.344293 6.370882 3.036 0.00513 **
## disp -0.019232 0.009371 -2.052 0.04960 *
## hp -0.031229 0.013345 -2.340 0.02663 *
## drat 2.714975 1.487366 1.825 0.07863 .
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 3.008 on 28 degrees of freedom
## Multiple R-squared: 0.775, Adjusted R-squared: 0.7509
## F-statistic: 32.15 on 3 and 28 DF, p-value: 3.28e-09Which regressors seem to have significant effect? Which of them seem irrelevant?
Model selection strategies
Considering the critical level of \(\alpha = 0.05\), we can not reject the null hypothesis \(H_0; \beta_4 = 0\), which (in words) suggests that the consumption of the car is independent of the rear axle ratio. Thus, instead of the model with 3 predictor variables we can consider a smaller (restricted) model with the remaining 2 covariates.
fit_add2 <- lm(mpg ~ disp + hp, data = mtcars)
(sumfit_add2 <- summary(fit_add2))##
## Call:
## lm(formula = mpg ~ disp + hp, data = mtcars)
##
## Residuals:
## Min 1Q Median 3Q Max
## -4.7945 -2.3036 -0.8246 1.8582 6.9363
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 30.735904 1.331566 23.083 < 2e-16 ***
## disp -0.030346 0.007405 -4.098 0.000306 ***
## hp -0.024840 0.013385 -1.856 0.073679 .
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 3.127 on 29 degrees of freedom
## Multiple R-squared: 0.7482, Adjusted R-squared: 0.7309
## F-statistic: 43.09 on 2 and 29 DF, p-value: 2.062e-09In the restricted model, using again the critical value of \(\alpha = 0.05\), we can again see that the null hypothesis \(H_0: \beta_2 = 0\) is not rejected – the corresponding \(p\)-value \(0.07368\) is slightly higher than \(0.05\). Thus, we can again consider a submodel, where the car consumption is only explained by the information about the engine displacement:
fit_add3 <- lm(mpg ~ disp, data = mtcars)
summary(fit_add3)##
## Call:
## lm(formula = mpg ~ disp, data = mtcars)
##
## Residuals:
## Min 1Q Median 3Q Max
## -4.8922 -2.2022 -0.9631 1.6272 7.2305
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 29.599855 1.229720 24.070 < 2e-16 ***
## disp -0.041215 0.004712 -8.747 9.38e-10 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 3.251 on 30 degrees of freedom
## Multiple R-squared: 0.7183, Adjusted R-squared: 0.709
## F-statistic: 76.51 on 1 and 30 DF, p-value: 9.38e-10In the model above, both statistical tests return significant \(p\)-value and the model can not be further reduced. Thus, we performed the model selection procedure. From all considered models we selected one final model that is (in some well-defined sense) the most appropriate one. This particular selection strategy is called the stepwise backward selection strategy.
Stepwise backward selection
The idea is to fit a full model firstly and, consecutively, to reduce the model by taking out the less significant predictors. The final model is the one in which no other predictor can be added. This is the procedure that we just applied above.
Stepwise forward selection
The idea is reverse. We start with all possible (three in this case) simple regression models (as we fitted them above) and we conclude that the most significant dependence is for the model with the dependence of the consumption on the displacement – compare the \(p\)-values below:
summary(fit_disp <- lm(mpg ~ disp, data = mtcars))##
## Call:
## lm(formula = mpg ~ disp, data = mtcars)
##
## Residuals:
## Min 1Q Median 3Q Max
## -4.8922 -2.2022 -0.9631 1.6272 7.2305
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 29.599855 1.229720 24.070 < 2e-16 ***
## disp -0.041215 0.004712 -8.747 9.38e-10 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 3.251 on 30 degrees of freedom
## Multiple R-squared: 0.7183, Adjusted R-squared: 0.709
## F-statistic: 76.51 on 1 and 30 DF, p-value: 9.38e-10summary(fit_hp <- lm(mpg ~ hp, data = mtcars))##
## Call:
## lm(formula = mpg ~ hp, data = mtcars)
##
## Residuals:
## Min 1Q Median 3Q Max
## -5.7121 -2.1122 -0.8854 1.5819 8.2360
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 30.09886 1.63392 18.421 < 2e-16 ***
## hp -0.06823 0.01012 -6.742 1.79e-07 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 3.863 on 30 degrees of freedom
## Multiple R-squared: 0.6024, Adjusted R-squared: 0.5892
## F-statistic: 45.46 on 1 and 30 DF, p-value: 1.788e-07summary(fit_drat <- lm(mpg ~ drat, data = mtcars))##
## Call:
## lm(formula = mpg ~ drat, data = mtcars)
##
## Residuals:
## Min 1Q Median 3Q Max
## -9.0775 -2.6803 -0.2095 2.2976 9.0225
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -7.525 5.477 -1.374 0.18
## drat 7.678 1.507 5.096 1.78e-05 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 4.485 on 30 degrees of freedom
## Multiple R-squared: 0.464, Adjusted R-squared: 0.4461
## F-statistic: 25.97 on 1 and 30 DF, p-value: 1.776e-05Thus, the model that we use to proceed further is the model where the
consumption is explained by the displacement. In the second step of the
stepwise forward selection procedure we look for another covariate (out
of two remaining ones, hp, or drat) which can
be added into the model (meaning that the corresponding \(p\)-value of the test is significant). We
consider two models:
fit_for1 <- lm(mpg ~ disp + hp, data = mtcars)
summary(fit_for1)##
## Call:
## lm(formula = mpg ~ disp + hp, data = mtcars)
##
## Residuals:
## Min 1Q Median 3Q Max
## -4.7945 -2.3036 -0.8246 1.8582 6.9363
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 30.735904 1.331566 23.083 < 2e-16 ***
## disp -0.030346 0.007405 -4.098 0.000306 ***
## hp -0.024840 0.013385 -1.856 0.073679 .
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 3.127 on 29 degrees of freedom
## Multiple R-squared: 0.7482, Adjusted R-squared: 0.7309
## F-statistic: 43.09 on 2 and 29 DF, p-value: 2.062e-09fit_for2 <- lm(mpg ~ disp + drat, data = mtcars)
summary(fit_for2)##
## Call:
## lm(formula = mpg ~ disp + drat, data = mtcars)
##
## Residuals:
## Min 1Q Median 3Q Max
## -5.1265 -2.2045 -0.5835 1.4497 6.9884
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 21.844880 6.747971 3.237 0.00302 **
## disp -0.035694 0.006653 -5.365 9.19e-06 ***
## drat 1.802027 1.542091 1.169 0.25210
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 3.232 on 29 degrees of freedom
## Multiple R-squared: 0.731, Adjusted R-squared: 0.7125
## F-statistic: 39.41 on 2 and 29 DF, p-value: 5.385e-09In both cases we observe the \(p\)-value for the added covariate which is
larger than \(0.05\). Thus, the final
model is the model denoted as fit_add3 or
fit_disp, where only disp is included.
Individual work
- Note, that both model selection strategies (backward and forward) returned the same final model. This is, however, not always the case.
- Discuss some obvious advantages and disadvantages of both selection strategies.
- What would happen if you also consider other covariates such as
wt,cyl,am,vs, \(\ldots\)?
cor(mtcars[,1:11])## mpg cyl disp hp drat wt qsec vs am
## mpg 1.0000000 -0.8521620 -0.8475514 -0.7761684 0.68117191 -0.8676594 0.41868403 0.6640389 0.59983243
## cyl -0.8521620 1.0000000 0.9020329 0.8324475 -0.69993811 0.7824958 -0.59124207 -0.8108118 -0.52260705
## disp -0.8475514 0.9020329 1.0000000 0.7909486 -0.71021393 0.8879799 -0.43369788 -0.7104159 -0.59122704
## hp -0.7761684 0.8324475 0.7909486 1.0000000 -0.44875912 0.6587479 -0.70822339 -0.7230967 -0.24320426
## drat 0.6811719 -0.6999381 -0.7102139 -0.4487591 1.00000000 -0.7124406 0.09120476 0.4402785 0.71271113
## wt -0.8676594 0.7824958 0.8879799 0.6587479 -0.71244065 1.0000000 -0.17471588 -0.5549157 -0.69249526
## qsec 0.4186840 -0.5912421 -0.4336979 -0.7082234 0.09120476 -0.1747159 1.00000000 0.7445354 -0.22986086
## vs 0.6640389 -0.8108118 -0.7104159 -0.7230967 0.44027846 -0.5549157 0.74453544 1.0000000 0.16834512
## am 0.5998324 -0.5226070 -0.5912270 -0.2432043 0.71271113 -0.6924953 -0.22986086 0.1683451 1.00000000
## gear 0.4802848 -0.4926866 -0.5555692 -0.1257043 0.69961013 -0.5832870 -0.21268223 0.2060233 0.79405876
## carb -0.5509251 0.5269883 0.3949769 0.7498125 -0.09078980 0.4276059 -0.65624923 -0.5696071 0.05753435
## gear carb
## mpg 0.4802848 -0.55092507
## cyl -0.4926866 0.52698829
## disp -0.5555692 0.39497686
## hp -0.1257043 0.74981247
## drat 0.6996101 -0.09078980
## wt -0.5832870 0.42760594
## qsec -0.2126822 -0.65624923
## vs 0.2060233 -0.56960714
## am 0.7940588 0.05753435
## gear 1.0000000 0.27407284
## carb 0.2740728 1.00000000Model selection criteria
There are also other selection strategies based on various selection criteria. Typically used criteria are, for instance, the Akaike’s Information Criterion (AIC) or Bayesian Information Criterion (BIC). But there are also others.
For the AIC criterion, there is a standard R function
AIC():
AIC(fit_add3)## [1] 170.2094### compare also with the AIC for the remaining two (simple) regression models
AIC(fit_hp)## [1] 181.2386AIC(fit_drat)## [1] 190.7999The BIC criterion is implemented, for instance, in the library
flexmix (installation with the command
install.packages("flexmix") is needed)
library(flexmix)## Warning: package 'flexmix' was built under R version 4.5.2## Loading required package: latticeBIC(fit_add3)## [1] 174.6066AIC(fit_add3, k=log(nobs(fit_add3))) # the same## [1] 174.6066### compare also with the BIC for the remaining two (simple) regression models
BIC(fit_hp)## [1] 185.6358BIC(fit_drat)## [1] 195.1971Individual work
- Consider both, AIC and BIC criterion and use them to perform the model selection approach. The smaller the value the better the fit.
- Use some literature or references and find out how AIC and BIC are calculated.
- What are some discussed advantages/disadvantages of all four model selection approaches?