Simple (ordinary) linear regression model with transformed covariate
Jan Vávra
Exercise 3
Download this R markdown as: R, Rmd.
Outline of the lab session:
Simple (ordinary) linear regression model for a continuous variable \(Y \in \mathbb{R}\) given a
- continuous explanatory variable \(X \in \mathbb{R}\) (simple transformations),
- binary explanatory variable \(X \in \mathbb{R}\) (different parametrizations).
Loading the data and libraries
Some necessary R packages (each package must be firstly installed in
R – this can be achieved by running the command
install.packages("package_name")). After the installation,
the libraries are initialized by
library(MASS)
library(ISLR2)The installation (command install.packages()) should be
performed just once. However, the initialization of the library – the
command library() – must be used every time when starting a
new R session.
1. Simple (ordinary) linear regression
The ISLR2 library contains the Boston data
set, which records medv (median house value) for \(506\) census tracts in Boston. We will seek
to predict medv using some of the \(12\) given predictors such as
rm (average number of rooms per house), age
(average age of houses), or lstat (percent of households
with low socioeconomic status).
head(Boston)## crim zn indus chas nox rm age dis rad tax ptratio lstat medv
## 1 0.00632 18 2.31 0 0.538 6.575 65.2 4.0900 1 296 15.3 4.98 24.0
## 2 0.02731 0 7.07 0 0.469 6.421 78.9 4.9671 2 242 17.8 9.14 21.6
## 3 0.02729 0 7.07 0 0.469 7.185 61.1 4.9671 2 242 17.8 4.03 34.7
## 4 0.03237 0 2.18 0 0.458 6.998 45.8 6.0622 3 222 18.7 2.94 33.4
## 5 0.06905 0 2.18 0 0.458 7.147 54.2 6.0622 3 222 18.7 5.33 36.2
## 6 0.02985 0 2.18 0 0.458 6.430 58.7 6.0622 3 222 18.7 5.21 28.7To find out more about the data set, we can type
?Boston.
We will start with some simple explanatory analysis. For all three explanatory variables we draw a simple scatterplot.
vars <- c("medv", "rm", "age", "lstat")
LABS <- c("Median house value [1000$]",
"Average number of rooms",
"Proportion of owner-occupied units built prior to 1940",
"Lower status of the population [%]")
names(LABS) <- vars
par(mfrow = c(1,3), mar = c(4,4,0.5,0.5))
plot(medv ~ rm, data = Boston, pch = 22, bg = "gray",
ylab = LABS["medv"], xlab = LABS["rm"])
plot(medv ~ age, data = Boston, pch = 22, bg = "gray",
ylab = LABS["medv"], xlab = LABS["age"])
plot(medv ~ lstat, data = Boston, pch = 22, bg = "gray",
ylab = LABS["medv"], xlab = LABS["lstat"])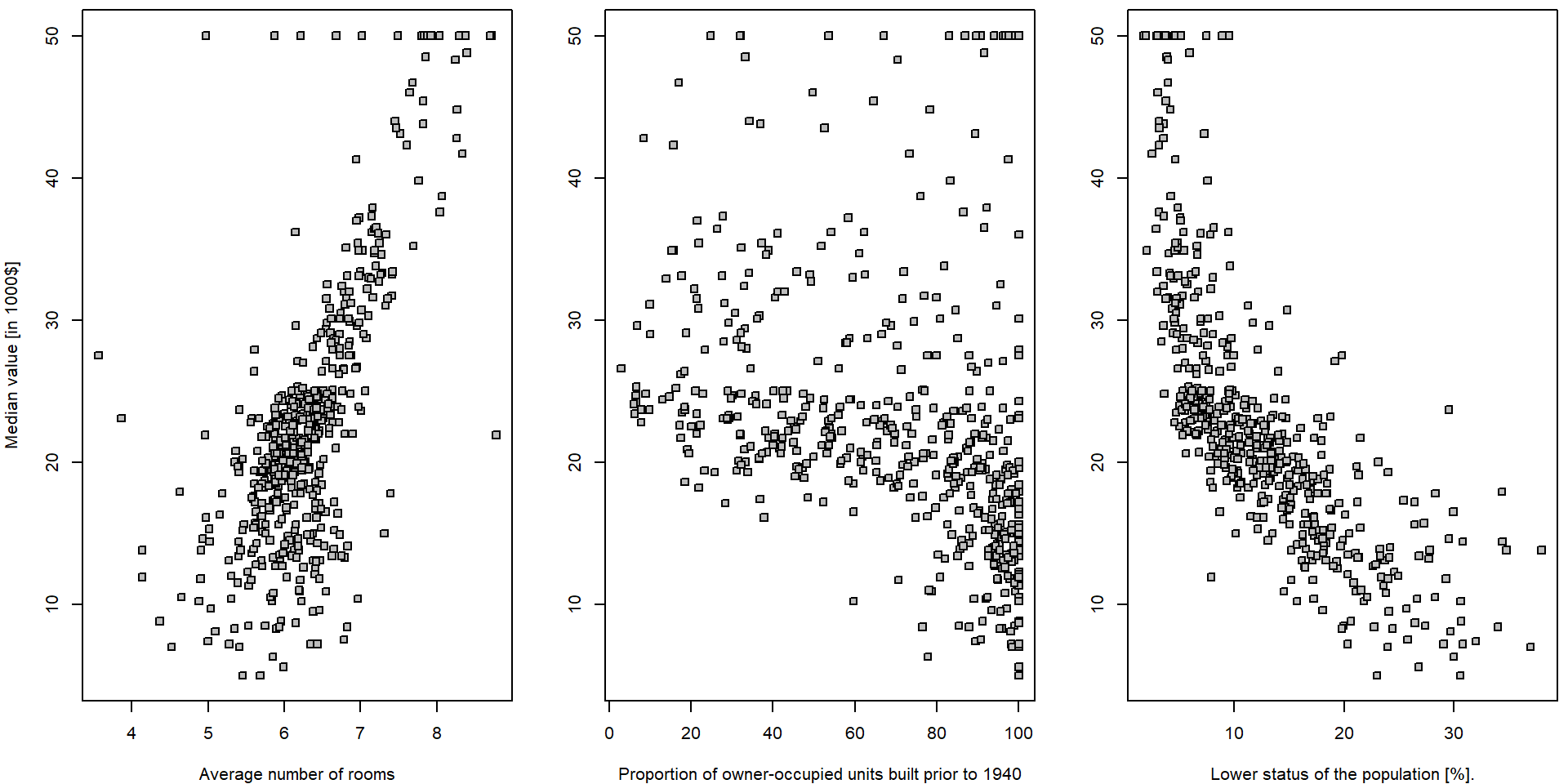
It seems that there is a positive (progressive) relationship between
the median house value (dependent variable medv) and the
average number of room in the house (independent variable
rm) and a negative relationship (regression) in terms of
the relationship between the median house value and the population
status (explanatory variable lstat). For the proportion of
the owner-occupied units build prior to 1940 (variable
age), it is not that much obvious what relationship to
expect… In all three situations we will go for a simple linear
(ordinary) regression model in terms of
\[ Y_i = a + b X_i + \varepsilon_i \qquad i = 1, \dots, 506. \]
Explorative analysis
summary(Boston[,vars])## medv rm age lstat
## Min. : 5.00 Min. :3.561 Min. : 2.90 Min. : 1.73
## 1st Qu.:17.02 1st Qu.:5.886 1st Qu.: 45.02 1st Qu.: 6.95
## Median :21.20 Median :6.208 Median : 77.50 Median :11.36
## Mean :22.53 Mean :6.285 Mean : 68.57 Mean :12.65
## 3rd Qu.:25.00 3rd Qu.:6.623 3rd Qu.: 94.08 3rd Qu.:16.95
## Max. :50.00 Max. :8.780 Max. :100.00 Max. :37.97apply(Boston[,vars], 2, sd)## medv rm age lstat
## 9.1971041 0.7026171 28.1488614 7.1410615cor(Boston[,vars])## medv rm age lstat
## medv 1.0000000 0.6953599 -0.3769546 -0.7376627
## rm 0.6953599 1.0000000 -0.2402649 -0.6138083
## age -0.3769546 -0.2402649 1.0000000 0.6023385
## lstat -0.7376627 -0.6138083 0.6023385 1.0000000ms <- qs <- list()
for(x in vars[2:4]){
qs[[x]] <- quantile(Boston[,x], seq(0,1, length.out = 5))
Boston[,paste0("f",x)] <- cut(Boston[,x], breaks = qs[[x]], include.lowest = TRUE)
ms[[x]] <- tapply(Boston$medv, Boston[,paste0("f",x)], mean)
}
fxs <- paste0("f",vars[2:4])
summary(Boston[,fxs])## frm fage flstat
## [3.56,5.89]:127 [2.9,45] :127 [1.73,6.95]:127
## (5.89,6.21]:126 (45,77.5] :126 (6.95,11.4]:126
## (6.21,6.62]:126 (77.5,94.1]:126 (11.4,17] :126
## (6.62,8.78]:127 (94.1,100] :127 (17,38] :127par(mfrow = c(1,3), mar = c(4,4,2,0.5))
for(x in fxs){
plot(x = Boston[,x], y = Boston$medv, ylab = LABS["medv"], xlab = LABS[substr(x, 2, nchar(x))])
}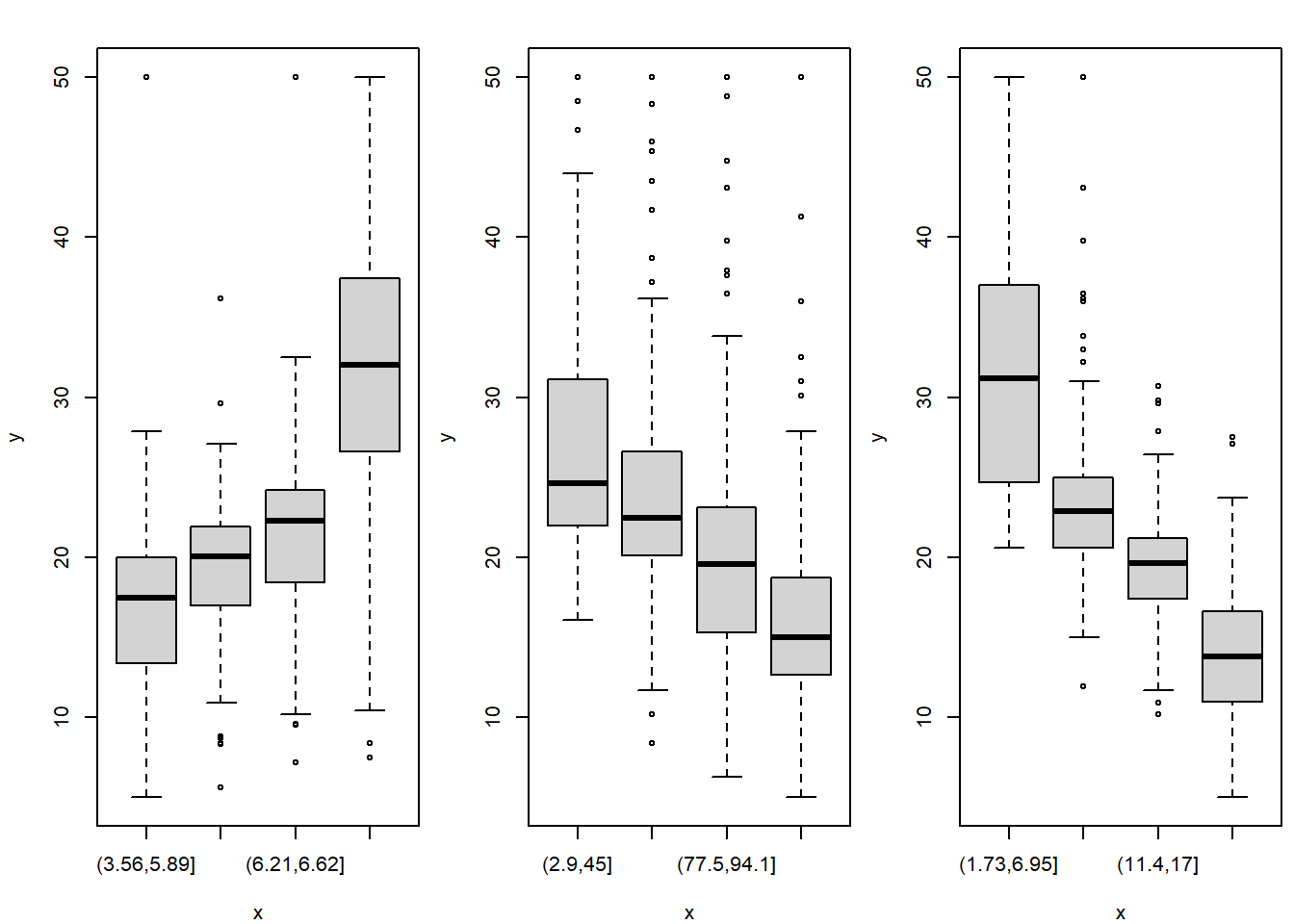
In order to get some insight into the relationship \(Y = f(X) + \varepsilon\) (and to judge the
appropriateness of the linear line to be used as a surrogate for \(f(\cdot)\)) we can take a look at some
(non-parametric) data smoothing – function lowess() in
R:
par(mfrow = c(1,3), mar = c(4,4,0.5,0.5))
for(x in vars[2:4]){
plot(as.formula(paste0("medv ~ ", x)), data = Boston, pch = 22, bg = "gray",
ylab = LABS["medv"], xlab = LABS[x])
lines(lowess(Boston$medv ~ Boston[,x], f = 2/3), col = "red", lwd = 2)
segments(x0 = qs[[x]][-length(qs[[x]])], x1 = qs[[x]][-1],
y0 = ms[[x]], lwd = 2, col = "darkviolet")
}
legend("topright", legend = c("lowess", "group-means"), col = c("red", "darkviolet"), lwd = 2, lty = 1)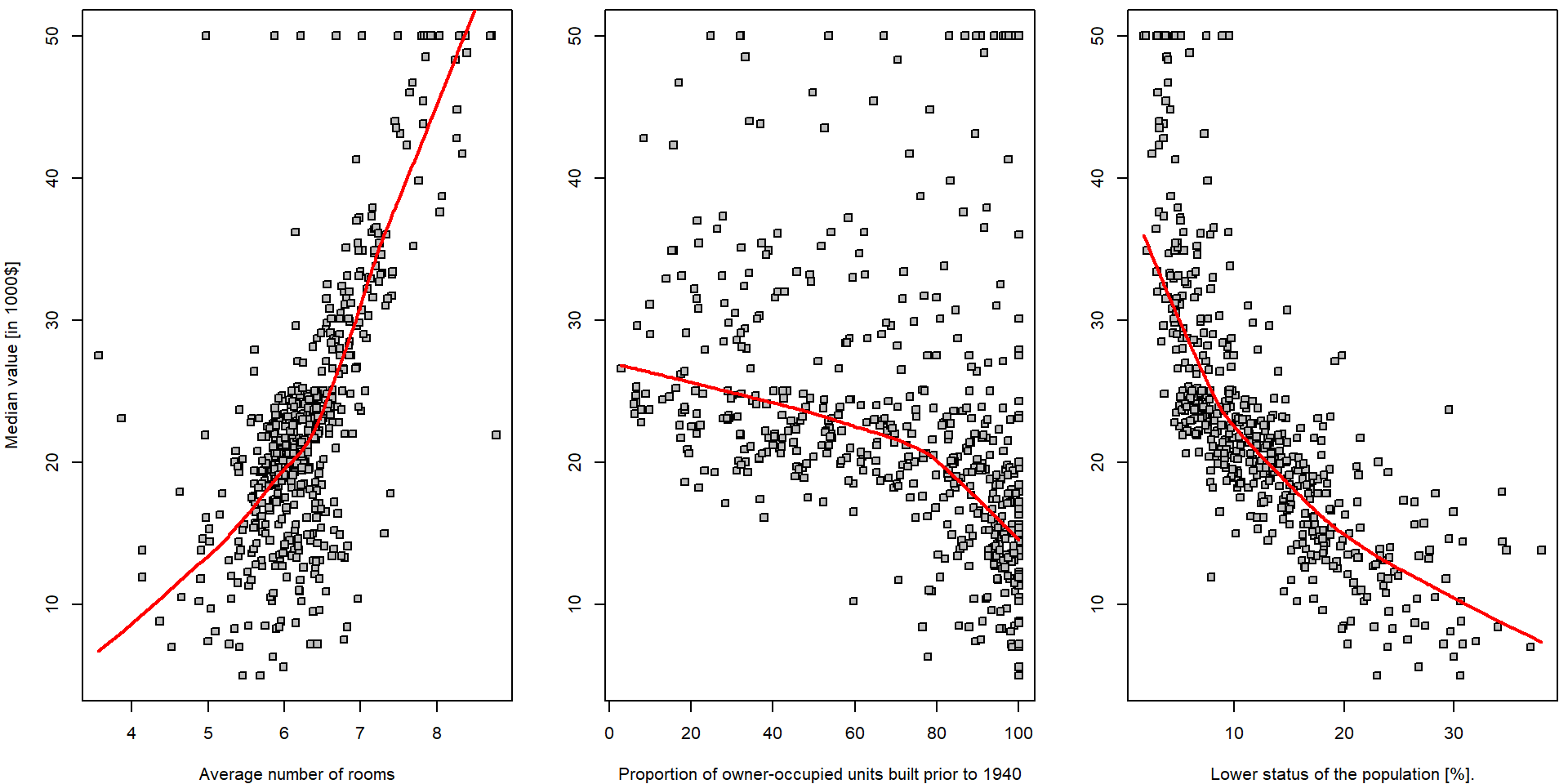
Note, that there is hardly any reasonable analytical expression for
the red curves above (the specific form of the function \(f(\cdot)\)). Also note the parameter
f = 2/3 in the function lowess(). Run the same
R code with different options for the value of this parameter to see
differences.
Explanatory variable lstat
We will now fit a simple linear regression line through the data
using the R function lm(). In the implementation used
below, the analytical form of the function \(f(\cdot)\) being used to “smooth” the data
is \[
f(x) = a + bx
\] for some intercept parameter \(a \in
\mathbb{R}\) and the slope parameter \(b \in \mathbb{R}\). The following R code
fits a simple linear regression line, with medv as the
response (dependent variable, outcome) and lstat as the
predictor (explanatory/independent variable/covariate). The basic syntax
is lm(y ~ x, data), where y is the response,
x is the predictor, and data is the data set
in which these two variables are kept.
lm.fit <- lm(medv ~ lstat, data = Boston)If we type lm.fit, only some basic information about the
model is output.
lm.fit##
## Call:
## lm(formula = medv ~ lstat, data = Boston)
##
## Coefficients:
## (Intercept) lstat
## 34.55 -0.95This fits a straight line through the data. The line intersects the \(y\) axis at the point \(34.55\). The slope parameter is estimated as \(-0.95\), which means that for each unit increase on the \(x\) axis the line drops by \(0.95\) units with respect to the \(y\) axis.
par(mfrow = c(1,1), mar = c(4,4,0.5,0.5))
plot(medv ~ lstat, data = Boston, pch = 22, bg = "gray",
ylab = LABS["medv"], xlab = LABS["lstat"])
lines(lowess(Boston$medv ~ Boston$lstat, f = 2/3), col = "red", lwd = 2)
abline(lm.fit, col = "blue", lwd = 2)
legend("topright", legend = c("lowess", "fitted line"), col = c("red", "blue"), lwd = 2, lty = 1)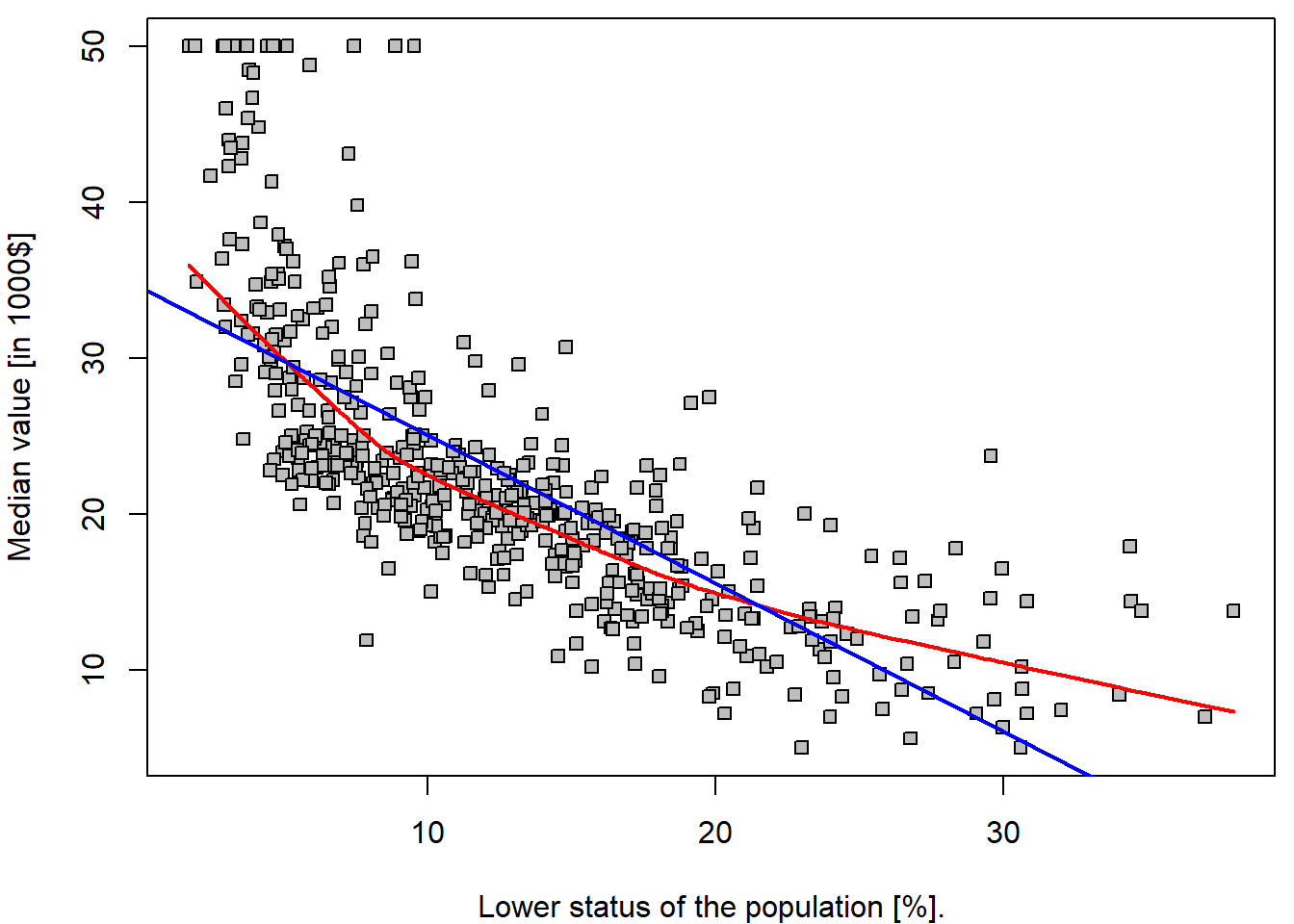
It is important to realize that the estimated parameters \(34.55\) and \(-0.95\) are a realization of two random variables – \(\widehat{a}\) and \(\widehat{b}\) (i.e., for another dataset, or another subset of the observations we would obtained different values of the estimated parameters). Thus, we are speaking about random quantities here and, therefore, it is reasonable to inspect some of their statistical properties (such as the corresponding mean parameters, variance of the estimates, or even their full distribution…).
Under normality of error terms \(\varepsilon_i \sim \mathsf{N}(0, \sigma^2)\), we know that \(Y_i | X_i \sim \mathsf{N}(a+bX_i, \sigma^2)\). Moreover, due to \[ w_i := \frac{X_i - \overline{X}_n}{\sum\limits_{j=1}^n\left(X_j - \overline{X}_n\right)^2}, \qquad \widehat{b} = \sum\limits_{i=1}^n Y_i w_i, \qquad \widehat{a} = \overline{Y}_n - \widehat{b} \overline{X}_n = \sum\limits_{i=1}^n Y_i \left(\frac{1}{n} - w_i\overline{X}_n\right) \] we obtain \[ \left. \begin{pmatrix} \widehat{a} \\ \widehat{b} \end{pmatrix} \middle| X_1, \ldots, X_n \sim \mathsf{N}_2\left( \begin{pmatrix} a \\ b \end{pmatrix}, \; \frac{\sigma^2}{\sum\limits_{i=1}^n(X_i - \overline{X}_n)^2} \begin{pmatrix} \frac{1}{n}\sum\limits_{i=1}^n X_i^2 & -\overline{X}_n \\ -\overline{X}_n & 1 \end{pmatrix} \right) \right. . \] Hence, natural estimator of the variance-covariance matrix is obtained by plugging-in the estimate (the residual standard error) for \(\sigma^2\) based on residual sum of squares: \[ \widehat{\sigma}_n^2 = \frac{1}{n-2} \sum\limits_{i=1}^n\left(Y_i - \widehat{a} - \widehat{b}X_i\right)^2. \]
Some of the statistical properties (i.e., the empirical estimates for
the standard errors of the estimates) and other useful quantities (\(R^2\) statistic and \(F\)-statistic) can be obtained by
summary():
(sum.lm.fit <- summary(lm.fit))##
## Call:
## lm(formula = medv ~ lstat, data = Boston)
##
## Residuals:
## Min 1Q Median 3Q Max
## -15.168 -3.990 -1.318 2.034 24.500
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 34.55384 0.56263 61.41 <2e-16 ***
## lstat -0.95005 0.03873 -24.53 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 6.216 on 504 degrees of freedom
## Multiple R-squared: 0.5441, Adjusted R-squared: 0.5432
## F-statistic: 601.6 on 1 and 504 DF, p-value: < 2.2e-16We can use the names() function in order to find out
what other pieces of information are stored in lm.fit.
Although we can extract these quantities by name,
e.g. lm.fit$coefficients, it is safer to use the extractor
functions like coef() to access them.
names(lm.fit)## [1] "coefficients" "residuals" "effects" "rank" "fitted.values" "assign"
## [7] "qr" "df.residual" "xlevels" "call" "terms" "model"lm.fit$coefficients## (Intercept) lstat
## 34.5538409 -0.9500494coef(lm.fit)## (Intercept) lstat
## 34.5538409 -0.9500494It is important to realize, that the estimates \(\widehat{a}\) and \(\widehat{b}\) are random variables. They have the corresponding variances \(\mathsf{var} (\widehat{a})\) and \(\mathsf{var} (\widehat{b})\) but the values that we see in the table above are just the estimates of (the square roots of) these theoretical quantities – thus, mathematically correctly, we should use the notation \[ \widehat{\mathsf{var}(\widehat{a})} \approx 0.5626^2 \qquad\text{and}\qquad \widehat{\mathsf{var}(\widehat{b})} \approx 0.03873^2 \] The values in the table (second column) are the estimates for the true standard errors of \(\widehat{a}\) and \(\widehat{b}\) (because we do not now the true variance, or standard error respectively, of the error terms \(\varepsilon_i\) in the underlying model \(Y_i = a + b X_i + \varepsilon_i\), where we only assume that \(\varepsilon_i \sim (0, \sigma^2)\)).
The third column t value of the summary contains the
t-test-like test statistics for testing hypothesis that
particular coefficient is equal to zero against the alternative of not
being equal to zero. It is computed simply as Estimate /
Std. Error. The last column than contains a p-value for
such test computed using quantiles of Student t-distribution with \(n-2\) degrees of freedom (see
lm.fit$df.residual).
# vcov() gives the estimate of variance covariance matrix for (hat(a),hat(b))^T
stderrs <- sqrt(diag(vcov(lm.fit)))
all.equal(stderrs, sum.lm.fit$coefficients[,"Std. Error"])## [1] TRUEtstats <- coef(lm.fit) / sum.lm.fit$coefficients[,"Std. Error"]
all.equal(tstats, sum.lm.fit$coefficients[,"t value"])## [1] TRUEpvals <- 2*pt(abs(tstats), df = lm.fit$df.residual, lower.tail = FALSE)
all.equal(pvals, sum.lm.fit$coefficients[,"Pr(>|t|)"])## [1] TRUEThe unknown variance \(\sigma^2 >
0\) is also estimated in the output above – see the value for the
Residual standard error. Thus, we have \(\widehat{\sigma^2} = 6.216^2\).
### model residuals -- estimates for random errors and their estimated variance/standard error
mean(lm.fit$residuals) # numerically zero due to presence of intercept## [1] 6.050431e-16var(lm.fit$residuals) # --> the same as squaring the residuals## [1] 38.55917sqrt(var(lm.fit$residuals)) # not exactly as in summary, var divides by (n-1) not (n-rank) ## [1] 6.209603sqrt(sum(lm.fit$residuals^2) / (nrow(Boston) - 1))## [1] 6.209603sqrt(sum(lm.fit$residuals^2) / lm.fit$df.residual)## [1] 6.21576The intercept parameter \(a \in
\mathbb{R}\) and the slope parameter \(b \in \mathbb{R}\) are unknown but fixed
parameters and we have the corresponding (point) estimates for both –
random quantities \(\widehat{a}\) and
\(\widehat{b}\). Thus, it is also
reasonable to ask for an interval estimates instead – the confidence
intervals for \(a\) and \(b\).
This can be obtained by the command confint().
confint(lm.fit)## 2.5 % 97.5 %
## (Intercept) 33.448457 35.6592247
## lstat -1.026148 -0.8739505cbind(coef(lm.fit) - qt(0.975, lm.fit$df.residual) * sum.lm.fit$coefficients[,"Std. Error"],
coef(lm.fit) + qt(0.975, lm.fit$df.residual) * sum.lm.fit$coefficients[,"Std. Error"])## [,1] [,2]
## (Intercept) 33.448457 35.6592247
## lstat -1.026148 -0.8739505The estimated parameters \(\widehat{a}\) and \(\widehat{b}\) can be used to estimate some
characteristic of the distribution of the dependent variable \(Y\) (i.e., medv) given the
value of the independent variable “\(X =
x\)” (i.e., lstat). In other words, the estimated
parameters can be used to estimate the conditional expectation of the
conditional distribution of \(Y\) given
“\(X = x\)”, respectively \[
\widehat{\mu_x} = \widehat{\mathsf{E}[Y | X = x]} = \widehat{a} +
\widehat{b}x.
\] The estimate for variance of such an estimate is derived from
the variance-covariance matrix: \[
\widehat{\mathsf{var}} \left( \widehat{a} + \widehat{b} x \right) =
\widehat{\mathsf{var}(\widehat{a})} +
2x\,\widehat{\mathsf{cov}(\widehat{a}, \widehat{b})} +
\widehat{\mathsf{var}(\widehat{b})} x^2,
\] which gives us the standard error of the following form: \[
\mathsf{SE}(x) = \widehat{\sigma}_n
\sqrt{\frac{\frac{1}{n}\sum\limits_{i=1}^n X_i^2 - 2 x \overline{X}_n +
x^2}{\sum\limits_{i=1}^n(X_i - \overline{X}_n)^2}}.
\]
However, sometimes it can be also useful to “predict” the value of \(Y\) for a specific value of \(X\). As far as \(Y\) is random (even conditionally on \(X = x\)) we need to give some characteristic of the whole conditional distribution – and this characteristic is said to be a prediction for \(Y\). It is common to use the conditional expectation for the point estimation, but the uncertainty evaluation proceeds differently.
If \(Y_\textsf{new}\) and \(X_\textsf{new}\) is a new pair of observations independent from the training data following the same model \(Y_\textsf{new} = a + b X_\textsf{new} + \varepsilon_\textsf{new}\), then random variables \(\widehat{a} + \widehat{b} X_\textsf{new}\) and \(\varepsilon_\textsf{new}\) are independent and the estimator of variance is a sum of two estimates:
- \(\widehat{\mathsf{var}} \left( \widehat{a} + \widehat{b} X_\textsf{new} \middle| X_\textsf{new} \right) = \widehat{\mathsf{var}(\widehat{a})} + 2X_\textsf{new}\,\widehat{\mathsf{cov}(\widehat{a}, \widehat{b})} + \widehat{\mathsf{var}(\widehat{b})} X_\textsf{new}^2 = \left(\mathsf{SE}(X_\textsf{new})\right)^2\),
- \(\widehat{\mathsf{var}}(\varepsilon_\textsf{new}) = \widehat{\sigma}_n^2\).
We call this quantity a standard error of prediction \[ \mathsf{SEP}(X_\textsf{new}) = \widehat{\sigma}_n \sqrt{\frac{\frac{1}{n}\sum\limits_{i=1}^n X_i^2 - 2 X_\textsf{new} \overline{X}_n + X_\textsf{new}^2}{\sum\limits_{i=1}^n(X_i - \overline{X}_n)^2}+ 1}. \]
In the R program, we can use the predict() function,
which also produces the confidence / prediction intervals for the
prediction of medv for a given value of
lstat.
fitted.values <- predict(lm.fit) # returns fitted values by default
all.equal(fitted.values, lm.fit$fitted.values)## [1] TRUE# Alternatively, we can supply specific x-values for which to predict
newdata <- data.frame(lstat = (c(5, 10, 15)))
# Manual computation of the point estimate
(point_est <- coef(lm.fit)[1] + coef(lm.fit)[2] * newdata$lstat)## [1] 29.80359 25.05335 20.30310## Confidence intervals for E[Y|X=x]
SEnew <- sapply(newdata$lstat, function(x){
sum.lm.fit$sigma * sqrt((mean(Boston$lstat^2) - 2*x*mean(Boston$lstat) + x^2)/sum((Boston$lstat-mean(Boston$lstat))^2))
})
# or alternatively
SEnew <- sapply(newdata$lstat, function(x){
sqrt(t(c(1, x)) %*% vcov(lm.fit) %*% c(1, x))
})
(ci_lower <- point_est - SEnew * qt(0.975, df = lm.fit$df.residual))## [1] 29.00741 24.47413 19.73159(ci_upper <- point_est + SEnew * qt(0.975, df = lm.fit$df.residual))## [1] 30.59978 25.63256 20.87461# Using PREDICT function
(pred.conf <- predict(lm.fit, newdata = newdata, interval = "confidence"))## fit lwr upr
## 1 29.80359 29.00741 30.59978
## 2 25.05335 24.47413 25.63256
## 3 20.30310 19.73159 20.87461## Prediction intervals for Y given X=x
SEPnew <- sapply(newdata$lstat, function(x){
sum.lm.fit$sigma * sqrt((mean(Boston$lstat^2) - 2*x*mean(Boston$lstat) + x^2)/sum((Boston$lstat-mean(Boston$lstat))^2) + 1)
})
# or alternatively
SEPnew <- sapply(newdata$lstat, function(x){
sqrt(t(c(1, x)) %*% vcov(lm.fit) %*% c(1, x) + sum.lm.fit$sigma^2)
})
(pi_lower <- point_est - SEPnew * qt(0.975, df = lm.fit$df.residual))## [1] 17.565675 12.827626 8.077742(pi_upper <- point_est + SEPnew * qt(0.975, df = lm.fit$df.residual))## [1] 42.04151 37.27907 32.52846# Using PREDICT function
(pred.pred <- predict(lm.fit, newdata = newdata, interval = "prediction"))## fit lwr upr
## 1 29.80359 17.565675 42.04151
## 2 25.05335 12.827626 37.27907
## 3 20.30310 8.077742 32.52846For instance, the 95,% confidence interval associated with a
lstat value of 10 is \((24.47,
25.63)\), and the 95,% prediction interval is \((12.83, 37.28)\). As expected, the
confidence and prediction intervals are centered around the same point
(a predicted value of \(25.05\) for
medv when lstat equals 10), but the latter are
substantially wider.
Practically, we can apply this approach to any \(X = x\). Even a dense grid of \(x\) values, which can be used for plotting purposes.
range(Boston$lstat)## [1] 1.73 37.97grid <- 0:40
pred_conf <- predict(lm.fit, newdata = data.frame(lstat = grid), interval = "confidence")
pred_pred <- predict(lm.fit, newdata = data.frame(lstat = grid), interval = "predict")
par(mfrow = c(1,1), mar = c(4,4,0.5,0.5))
plot(medv ~ lstat, data = Boston, pch = 22, bg = "gray",
ylab = LABS["medv"], xlab = LABS["lstat"])
lines(lowess(Boston$medv ~ Boston$lstat, f = 2/3), col = "red", lwd = 2)
abline(lm.fit, col = "blue", lwd = 2)
lines(x = grid, y = pred_conf[,"lwr"], col = "darkviolet", lty = 2, lwd = 2)
lines(x = grid, y = pred_conf[,"upr"], col = "darkviolet", lty = 2, lwd = 2)
lines(x = grid, y = pred_pred[,"lwr"], col = "chocolate", lty = 3, lwd = 2)
lines(x = grid, y = pred_pred[,"upr"], col = "chocolate", lty = 3, lwd = 2)
legend("topright",
legend = c("lowess", "fitted line", "95% confidence", "95% prediction"),
col = c("red", "blue", "darkviolet", "chocolate"),
lwd = 2, lty = c(1,1,2,3))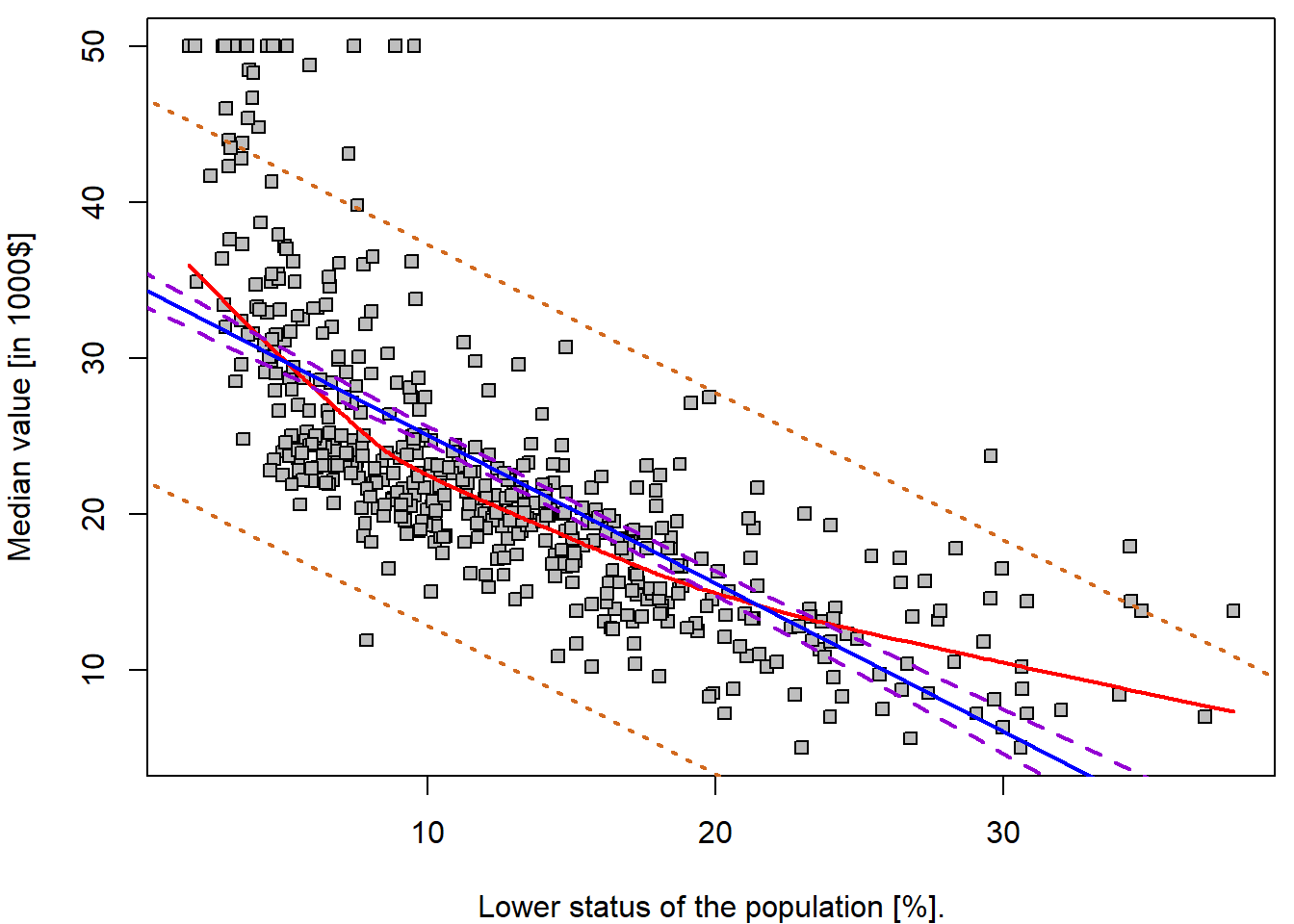
Some “goodness-of-fit” diagnostics
Next we examine some diagnostic plots – but we will discuss different diagnostics tools later.
Four diagnostic plots are automatically produced by applying the
plot() function directly to the output from
lm(). In general, this command will produce one plot at a
time, and hitting Enter will generate the next plot. However,
it is often convenient to view all four plots together. We can achieve
this by using the par() and mfrow() functions,
which tell R to split the display screen into separate
panels so that multiple plots can be viewed simultaneously. For example,
par(mfrow = c(2, 2)) divides the plotting region into a
\(2 \times 2\) grid of panels:
par(mfrow = c(2, 2), mar = c(4,4,2,0.5))
plot(lm.fit)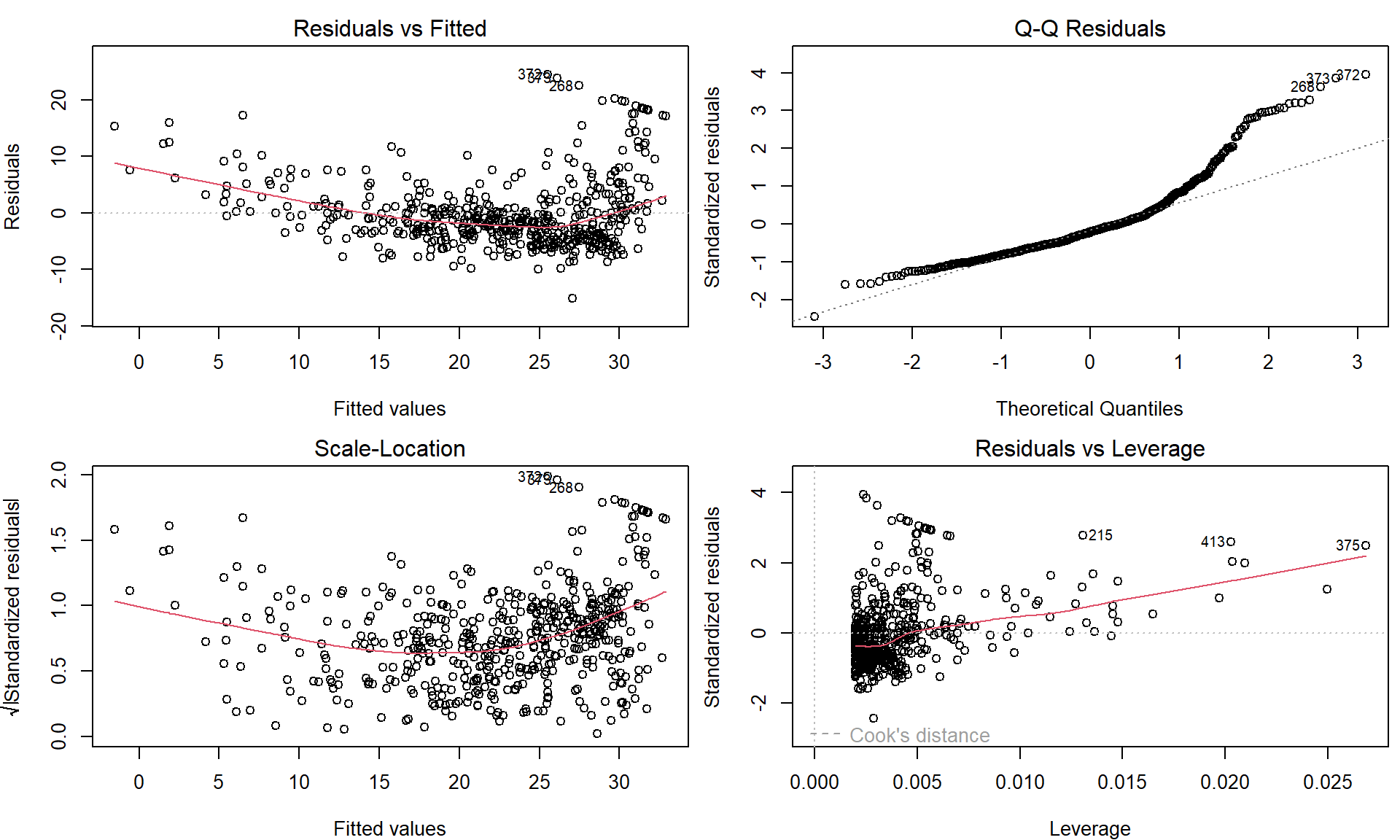
These plots can be used to judge the quality of the model that was used – in our particular case we used a simple linear regression line of the form \(Y = a + bX + \varepsilon\).
Individual work
- Repeat the previous R code and fit simple linear regression models
also for the remaining explanatory variable mentioned at the beginning –
ageandrm. - Compare the quality of all three models – visually by looking at the scatterplot and the fitted line and, also, by looking at four diagnostic plots as shown above.
- Which of the three models is the one that you consider the most reliable? Which one do you consider mostly unreliable?
- Is there any relationship/expectation with respect to the estimated covariances and correlations below?
cov(Boston$medv, Boston$rm)## [1] 4.493446cov(Boston$medv, Boston$age)## [1] -97.58902cov(Boston$medv, Boston$lstat)## [1] -48.44754cor(Boston$medv, Boston$rm)## [1] 0.6953599cor(Boston$medv, Boston$age)## [1] -0.3769546cor(Boston$medv, Boston$lstat)## [1] -0.73766272. Transformations of the predictor variable \(X\)
Fitting a line into our data is usually not suitable. But perhaps there exists some transformation of the independent covariate \(X\) such that it linearizes the relationship to the response \(Y\).
First, we discuss some trivial transformations. Consider the original model
lm.fit##
## Call:
## lm(formula = medv ~ lstat, data = Boston)
##
## Coefficients:
## (Intercept) lstat
## 34.55 -0.95and the model
lm(medv ~ I(lstat/10), data = Boston)##
## Call:
## lm(formula = medv ~ I(lstat/10), data = Boston)
##
## Coefficients:
## (Intercept) I(lstat/10)
## 34.55 -9.50Notice that transformed explanatory variable is enclosed within
I() function, which guarantees the usual mathematical
meaning, which may not correspond to the meaning of mathematical
notation within the formula class.
What type of transformation is used in this example and what is the underlying interpretation of this different parametrization of \(X\)? Such and similar parametrization are typically used to improve the interpretation of the final model. Remember, under \(Y = a + b X + \varepsilon\) the interpretation of \(b\) is \[ b = \mathsf{E}\left[Y \middle| X=x+1 \right] - \mathsf{E}\left[Y \middle| X=x \right], \] which changes with the change of scale and the meaning of a unit addition. In the scaled model the new interpretation is more appealing:
“A suburb has the expected median house value lower by 9.5 thousand dollars when compared to a suburb with lower status of population higher by 10%.”
Next, using the first model lm.fit the interpretation of
the estimated intercept parameter \(\widehat{a}\) can be given as follows:
“The estimated expected value for the median house value is 34.55 thousand dollars if the lower population status is at the zero level.”
But this may not be realistic when looking at the data – indeed, the
minimum observed value for lstat is \(1.73\). Thus, it can be more suitable to
use a different interpretation of the intercept parameter. Consider the
following model and the summary statistics for lstat:
lm(medv ~ I(lstat - 11.36), data = Boston)##
## Call:
## lm(formula = medv ~ I(lstat - 11.36), data = Boston)
##
## Coefficients:
## (Intercept) I(lstat - 11.36)
## 23.76 -0.95summary(Boston$lstat)## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 1.73 6.95 11.36 12.65 16.95 37.97What is the interpretation of the intercept parameter estimate in this case? Can you obtain the value of the estimate using the original model?
The transformations of the independent covariates can be, however, also used to improve the model fit. For instance, consider the following model
Boston$lstat_transformed <- sqrt(Boston$lstat)
lm.fit_sqrt <- lm(medv ~ lstat_transformed, data = Boston)Both models can be compared visually:
par(mfrow = c(1,3), mar = c(4,4,2,0.5))
plot(medv ~ lstat, data = Boston, pch = 22, bg = "gray",
ylab = LABS["medv"], xlab = LABS["lstat"],
main = "Original scale X - linear trend")
abline(lm.fit, col = "blue", lwd = 2)
plot(medv ~ lstat_transformed, data = Boston, pch = 22, bg = "gray",
ylab = LABS["medv"], xlab = sub("%", "sqrt(%)", LABS["lstat"]),
main = "Square root of X")
abline(lm.fit_sqrt, col = "blue", lwd = 2)
plot(medv ~ lstat, data = Boston, pch = 22, bg = "gray",
ylab = LABS["medv"], xlab = LABS["lstat"],
main = "Sqrt X fit on original scale")
xGrid <- seq(0,40, length = 1000)
yValues <- lm.fit_sqrt$coeff[1] + lm.fit_sqrt$coeff[2] * sqrt(xGrid)
lines(yValues ~ xGrid, col = "blue", lwd = 2)![]()
Note, that the first plot is the scatterplot for the relationship
medv \(\sim\)
lstat – which is the original model which fits the straight
line through the data. The middle plot is the scatterplot for the
relationship medv \(\sim
(\)lstat\()^{1/2}\)
and the corresponding model (lm.fit4) again fits the
straight line through the data (with coordinates \((Y_i, \sqrt{X_i})\)). Finally, the third
plot shows the original scatterplot (the data with the coordinates \((Y_i, X_i)\)) but the model
lm.fit_sqrt does not fit a straight line through such data.
The interpretation is simple with respect to the transformed data \((Y_i, \sqrt{X_i})\) but it is not that much
straightforward with respect to the original data \((Y_i, X_i)\).
Nevertheless, it seems that the model lm.fit_sqrt fits
the data more closely than the model lm.fit. However, could
we find even better curve?
Individual work
- Think of some alternative transformation of the original data in order to improve the overall fit of the model.
- Do not care for the interpretation issues for now, only focus on some reasonable approximation that will help to improve the quality of the fit.
- Try to obtain some quantitative characteristic for the quality of the fits – for instance, the residual sum of squares.
fits <- list()
fits[["lin"]] <- lm(medv ~ lstat, data = Boston)
fits[["sqrt"]] <- lm(medv ~ I(sqrt(lstat)), data = Boston)
fits[["cbrt"]] <- lm(medv ~ I(lstat^(1/3)), data = Boston)
fits[["log"]] <- lm(medv ~ I(log(lstat)), data = Boston)
# Evaluate the summary for all models by one command
summaries <- lapply(fits, summary)
# Comparison via Akaike's Information Criterion
unlist(lapply(fits, AIC))## lin sqrt cbrt log
## 3288.975 3201.659 3175.046 3133.187# Comparison via the residual error
unlist(lapply(summaries, function(s){s$sigma}))## lin sqrt cbrt log
## 6.215760 5.701943 5.553955 5.328915# Comparison via R^2
unlist(lapply(summaries, function(s){s$r.squared}))## lin sqrt cbrt log
## 0.5441463 0.6163964 0.6360501 0.6649462# ... possibly other ...
COL <- c("blue", "red", "darkviolet", "darkgreen")
names(COL) <- names(fits)
newdata <- data.frame(lstat = seq(min(Boston$lstat), max(Boston$lstat),
length.out = 100))
par(mfrow = c(1,1), mar = c(4,4,0.5,0.5))
plot(medv ~ lstat, data = Boston, pch = 22, bg = "gray",
ylab = LABS["medv"], xlab = LABS["lstat"])
for(t in names(fits)){
pred <- predict(fits[[t]], newdata = newdata)
lines(x = newdata$lstat, y = pred, col = COL[t], lwd = 2)
}
legend("topright", legend = c("linear", "square root", "cubic root", "logarithm"),
col = COL, lwd = 2, lty = 1)![]()
3. Binary explanatory variable \(X\)
Until now, the explanatory variable \(X\) was treated as a continuous variable. However, this variable can be also used as a binary information (and also as a categorical variable, but this will be discussed later).
We already mentioned a situation where the proportion of the owner-occupied houses is below 50% and above. Thus, we will create another variable in the original data that will reflect this information.
Boston$Iage <- (Boston$age > 50)
table(Boston$Iage)##
## FALSE TRUE
## 147 359We can look at both subpopulations by the means of two boxplots for instance:
par(mfrow = c(1,1), mar = c(4,4,0.5,0.5))
boxplot(medv ~ Iage, data = Boston, col = "lightblue",
xlab = "Proportion of owner-occupied houses prior to 1940 is above 50%",
ylab = LABS["medv"])
The figure above somehow corresponds with the scatterplot of
medv against age where we observed that higher
proportion (i.e., higher values of the age variable) are
associated with rather lower median house values (dependent variable
\(Y \equiv\) medv). In the
boxplot above, we can also see that higher proportions of the
owner-occupied houses prior to 1940 (the sub-population where the
proportion is above \(50\%\)) are
associated with rather lower median house values.
What will happen when this information (explanatory variable
Iage which only takes two values – one for true and zero
otherwise) will be used in a simple linear regression model?
lm.fit2 <- lm(medv ~ Iage, data = Boston)
lm.fit2##
## Call:
## lm(formula = medv ~ Iage, data = Boston)
##
## Coefficients:
## (Intercept) IageTRUE
## 26.693 -5.864And the correponding statistical summary of the model:
summary(lm.fit2)##
## Call:
## lm(formula = medv ~ Iage, data = Boston)
##
## Residuals:
## Min 1Q Median 3Q Max
## -15.829 -5.720 -1.729 2.898 29.171
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 26.6932 0.7267 36.730 < 2e-16 ***
## IageTRUE -5.8639 0.8628 -6.796 3.04e-11 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 8.811 on 504 degrees of freedom
## Multiple R-squared: 0.08396, Adjusted R-squared: 0.08214
## F-statistic: 46.19 on 1 and 504 DF, p-value: 3.038e-11Can you see some analogy with the following (partial) exploratory characteristic (respectively their sample estimates)?
mean(Boston$medv[Boston$Iage == F])## [1] 26.6932mean(Boston$medv[Boston$Iage == T])## [1] 20.82925mean(Boston$medv[Boston$Iage == T]) - mean(Boston$medv[Boston$Iage == F])## [1] -5.863949confint(lm.fit2)## 2.5 % 97.5 %
## (Intercept) 25.265377 28.121017
## IageTRUE -7.559073 -4.168825t.test(medv ~ Iage, data = Boston, var.equal = TRUE)##
## Two Sample t-test
##
## data: medv by Iage
## t = 6.7964, df = 504, p-value = 3.038e-11
## alternative hypothesis: true difference in means between group FALSE and group TRUE is not equal to 0
## 95 percent confidence interval:
## 4.168825 7.559073
## sample estimates:
## mean in group FALSE mean in group TRUE
## 26.69320 20.82925The estimated model in this case takes a form \[ Y = a + bX + \varepsilon \] where \(x\) can only take two specific values – it is either equal to zero and, thus, the model becomes \(f(x) = a\) or the value of \(x\) is equal to 1 and the model becomes \(f(x) = a + b\).
par(mfrow = c(1,1), mar = c(4,4,0.5,0.5))
plot(medv ~ age, data = Boston, pch = 22, bg = "gray",
ylab = LABS["medv"], xlab = LABS["age"])
segments(x0 = c(0, 50), x1 = c(50, 100),
y0 = c(coef(lm.fit2)[1], sum(coef(lm.fit2))),
col = "darkviolet", lwd = 2)
Note, that any other parametrization of the explanatory variable \(X\) (for instance, \(x = -1\) for the subpopulation with the proportion below 50% and \(x = 1\) for the subpopulation with the proportion above 50%) gives mathematically equivalent model.
### different parametrization of two subpopulations (using +/- 1 instead of 0/1)
Boston$Iage2 <- (2 * as.numeric(Boston$Iage) - 1)
head(Boston)## crim zn indus chas nox rm age dis rad tax ptratio lstat medv frm fage
## 1 0.00632 18 2.31 0 0.538 6.575 65.2 4.0900 1 296 15.3 4.98 24.0 (6.21,6.62] (45,77.5]
## 2 0.02731 0 7.07 0 0.469 6.421 78.9 4.9671 2 242 17.8 9.14 21.6 (6.21,6.62] (77.5,94.1]
## 3 0.02729 0 7.07 0 0.469 7.185 61.1 4.9671 2 242 17.8 4.03 34.7 (6.62,8.78] (45,77.5]
## 4 0.03237 0 2.18 0 0.458 6.998 45.8 6.0622 3 222 18.7 2.94 33.4 (6.62,8.78] (45,77.5]
## 5 0.06905 0 2.18 0 0.458 7.147 54.2 6.0622 3 222 18.7 5.33 36.2 (6.62,8.78] (45,77.5]
## 6 0.02985 0 2.18 0 0.458 6.430 58.7 6.0622 3 222 18.7 5.21 28.7 (6.21,6.62] (45,77.5]
## flstat lstat_transformed Iage Iage2
## 1 [1.73,6.95] 2.231591 TRUE 1
## 2 (6.95,11.4] 3.023243 TRUE 1
## 3 [1.73,6.95] 2.007486 TRUE 1
## 4 [1.73,6.95] 1.714643 FALSE -1
## 5 [1.73,6.95] 2.308679 TRUE 1
## 6 [1.73,6.95] 2.282542 TRUE 1lm.fit3 <- lm(medv ~ Iage2, data = Boston)
lm.fit3##
## Call:
## lm(formula = medv ~ Iage2, data = Boston)
##
## Coefficients:
## (Intercept) Iage2
## 23.761 -2.932# The same plot as before, however, based on lm.fit3
par(mfrow = c(1,1), mar = c(4,4,0.5,0.5))
plot(medv ~ age, data = Boston, pch = 22, bg = "gray",
ylab = LABS["medv"], xlab = LABS["age"])
segments(x0 = c(0, 50), x1 = c(50, 100),
y0 = c(coef(lm.fit3)[1]-coef(lm.fit3)[2], sum(coef(lm.fit3))),
col = "darkviolet", lwd = 2)
Individual work
Usually, with different parametrization we obtain different
interpretation options and statistical characteristics for different
quantities when calling the function summary().
- What is the interpretation of the estimates \(\widehat{a}\) and \(\widehat{b}\) in this case?
- Recall, that the model \(f(x) = a + bx\) for \(x = \pm 1\) takes now the form \(f(x) = a - b\) if the proportion is below \(50\%\) and the model becomes \(f(x) = a + b\) if the proportion is above \(50\%\).
- Can you reconstruct both estimates for subpopulations means using the model above?
- Try to think of some other parametrization of the independent variable \(X\) (the information whether the proportion is above or below \(50\%\)).
- In the model above we have the estimate for the intercept parameter \(\widehat{a} = 23.76\). Can you guess what does it stands for? What theoretical characteristic does it estimate?
(mean(Boston$medv[Boston$Iage2 == -1]) + mean(Boston$medv[Boston$Iage2 == 1]))/2## [1] 23.76122- Recall, that two subpopulations are not equal with respect to their size. What would be estimated by the intercept parameter estimate \(\widehat{a}\) if both subpopulations would be equal with respect to the size (i.e., balanced data)?
- Compare
summary()outputs for the two models. Which quantities are the same for both parametrizations? - How would you fit a model where coefficients correspond to individual groups (no intercept)?